فرآیند کشف دانش از داده KDD در داده کاوی با متلب – مرور مفاهیم

مثالی از داده کاوی:
به عنوان مثال فرض می کنیم گوگل در ابتدای کارش یک نقشه ساده از لینک های موجود در اینترنت داشته است، وقتی شخصی چیزی را سرچ می کرد در صفحه اول ده لینک لیست می شد و شخص به هر دلیلی به طور مستقیم لینک سوم را انتخاب می کرد.
مثالی از داده کاوی:
به عنوان مثال فرض می کنیم گوگل در ابتدای کارش یک نقشه ساده از لینک های موجود در اینترنت داشته است، وقتی شخصی چیزی را سرچ می کرد در صفحه اول ده لینک لیست می شد و شخص به هر دلیلی به طور مستقیم لینک سوم را انتخاب می کرد. به مرور وقتی انتخاب لینک سوم توسط کاربران زیاد شد گوگل متوجه شد که لینک سوم از محبوبیت بیشتری برخوردار است و باید در جایگاه اول قرارگیرد. بدین ترتیب به مرور زمان گوگل به یک موتور جستجوی قوی تبدیل شد و به مرور صفحات براساس محبوبیت و بازدید کاربران نمایش داده می شود.
پروسه داده کاوی:
همانطور که با کاوش در معادن و خروارها سنگ و ماسه طلا یافت می شد با کاوش در داده های خام نیز دانشی باارزش استخراج می شود.
حلقه ارتباطی بین داده و دانش:
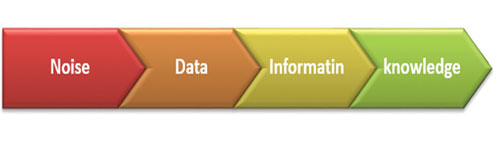
شکل ۱: Knowledge Discovery From Data
خلاصه ای از تاریخچه داده کاوی:
دهه ۱۹۶۰ و قبل از آن: ایجاد پایگاه های داده و جمع آوری داده
از دهه ۱۹۷۰ تا اواسط ۱۹۸۰: سیستم های مدیریت پایگاه داده
از اواسط ۱۹۸۰ تا حال: سیستم های پایگاه داده پیشرفته
از اواخر ۱۹۸۰ تا حال: تحلیل پیشرفته داده (شامل داده کاوی)
نکته: داده کاوی یک مسئله است(استخراج دانش از مجموعه ای از داده ها) نه مجموعه ای از روش ها
کاربردی از داده کاوی در علوم مختلف: در تحلیل اقتصادی و مالی، تحلیل شبکه های اجتماعی مثل فیسبوک و IMDB، بانکداری، مخابرات، ارتباطات، چت روم های یاهو بعدا کشف شد محلی بوده برای انتقال اطلاعات برای مقاصد خاص و اگر ارتباطات و الگوهای موجود کشف می شد می توانست بسیار مفید باشد، به طور مشابه می توان از این طریق به مبارزه با مفاسد دیگر مثل پول شویی پرداخت.
مراحل کشف دانش:
نکته: مراحل ۱ تا ۴ مراحل پیش پردازش داده ها هستند و ممکن است برای مجموعه ای از داده ها ضروری نباشند.
- پاکسازی داده ها: داده های پرت و دارای نویز شناسایی و حذف می شوند.
- تجمیع داده ها: جمع آوری داده به صورت یک مجموعه
- کوتاه سازی یا انتخاب داده ها: انتخاب داده های مربوط
- انتقال داده: نگاشت داده در فضاهای مختلف، به طور مثال سنجش تحصیلی در ایران ۱-۲۰ محاسبه می شود در کشوری دیگر ۰-۴ و در آمریکا حروف در این صورت به منظور انجام عملیات بر روی داده های مختلف باید داده ها نرمالسازی شوند.
- داده کاوی: داده کاوی فرآیند کشف دانش و الگوهای جالب از مقدار قابل توجهی از داده است.
- صحت سنجی: بر اساس معیارهای خاصی تعیین می شود که آیا الگوی بدست آمده معتبر و ارزشمند است یا خیر.
- ارائه دانش: ارائه دانش بدست آمده به کمک جداول، نمودارها با هدف حصول سریع به جمع بندی
مثال: با جستجوی عبارت Self-organizing map در گوگل به مقاله ای در ویکی پدیا دسترسی پیدا می کنیم با موضوع تحلیل نتایج انتخابات کنگره آمریکا، در این مقاله حجم عظیمی از اطلاعات و دانش بدست آمده در ۲۰ نمودار به صورت فشرده نمابش داده شده است.
ابزارهای داده کاوی:
- Matlab, c#, c++, VB, Perl, Python, R…
- Java, Weka…
- IBM SPSS Modeler Clementine…
- Microsoft SQL…
نکته: در این آموزش از متلب استفاده می شود اما الگوریتم ها در زبان های مختلف ثابت و قابل ترجمه از زبانی به زبان دیگر هستند.چه نوع داده هایی قابلیت کاوش
دارند؟
انواع داده های ساده:
- داده های ارتباطی پایگاه داده
- داده های مخزن داده
- داده های معاملاتی و مبادلاتی
انواع پیچیده تر داده(غیرخطی):
صدا، تصویر، متن، داده های جریانی، داه های درختی و…
چه نوع الگوهایی قابل شناسایی هستند:
توصیفی: معمولا بر اساس طبقه بندی است و کمک می کند پدیده ای را بهتر بشناسیم. مثال: توصیف ویژگی های خرید مشکوک از کارت های اعتباری
پیش بین: معمولا یر اساس شناخت گذشته ی پدیده ای مدلی را ایجاد می کند و رفتار آینده اش را پیش بینی می کند.
انواع الگوهای قابل کاوش:
- Class or Concept Description
- Characterization: there are some defined characterizations for a class, this pattern checks the input’s characterizations and if it was the same as the target class, the input is from that class.
- Discrimination: it assumes that the input is from class A, and then compares it with other classes and if they were not the same, it is from class A.
- Frequent Pattern, Association, and Correlation
- Classification and Regression for predictive Analysis
- Cluster Analysis
- Anomaly Detection: outlier Detection
الگوی مهم، در بردارنده دانش است:
- به راحتی قایل فهم برای انسان است.
- برای مجموعه ای جدید از داده ها معتبر است.
- به طور بالقوه کارآمد است.
- نوگرایانه باشد.
- بر یک پیش فرض منطقی صحه بگذارد.
دشواری های موجود در مسیر داده کاوی:
روش های داده کاوی: برای مسئله داده کاوی روش معینی وجود ندارد و معمولا باید از چندین روش استفاده کرد که باید بین تمامی این روش ها ارتباط برقرار کرد. همچنین معیاری برای تشخیص بهترین روش وجود ندارد.
ارتباط با کاربر: گاهی ارتباط دو طرفه با کاربر وجود دارد و ممکن است دریافت عکس العمل از کاربر مشکل باشدو همچنین نمایش برخی نتایج برای انسان مشکل است و…
کارایی و مقیاس پذیری: با افزایش تعداد ویژگی ها یا ابعاد یا سایز داده ها کارایی پائین می آید.
تنوع داده های قابل کاوش: نمی توان برای انواع داده رویکرد کلی پیشنهاد کرد.
ارتباط داده کاوی با مباحث حقوقی و اجتماعی: حریم خصوصی افراد دچار مشکل می شود، سوء استفاده از نتایج داده کاوی
کیفیت داده ها همواره به طور مناسب در اختیار نیستند و باید قبل از فرایند داده کاوی پیش پردازش شوند:
پاکسازی داده ها،تجمیع داده ها، کوتاه سازی یا انتخاب داده ها، انتقال داده
پاکسازی داده ها:
۱- مقادیر بدون مقدار یا گمشده:
الف) حذف رکورد (آسان ترین راه حل که باید تا حد توان اجتناب شود.)
ب) با مقادیر منطقی پر می کنیم. (این راه حل نیز ساده و مشکل برانگیز است.)
پ) استفاده از یک ثابت سراسری N/A, NAN,-1,…
ت) استفاده از یک معیار مرکزی مانند میانگین یا میانه (انتخاب معیار بستگی به شرایط دارد برای مثال وقتی توزیع داده ها متقارن است میانگین و وقتی توزیع دارای چولگی است میانه مناسب تر است و یا وقتی داده ها گسسته هستند عدد میانه حتما در بین مقادیر موجود است اما میانگین لزوما در بین مقادیرنیست.)
ث) استفاده از یک معیار مرکزی مربوط به همان کلاس
ج) استفاده از مقادیر شایع و پر احتمال (مد)
نکته: موارد الف – ب و پ بهتر است اولین انتخاب نباشند و موارد پ- ت- ث و ج سوگیری دارند.
۲- داده های آلوده به نویز :
الف) رگرسیون
ب) دسته بندی
پ) تحلیل داده های پرت
تجمیع داده ها:
- اسامی فیلد های مختلف
- حذف فیلدهای اضافی و وابسته
- داده تکراری
- ناهمخوانی مقداری بین فیلدها
کاهش و انتخاب داده ها (به علت کمبود حافظه و زمان):
۱- کاهش ابعاد
الف) انتخاب زیرمجموعه ای از ویژگی ها با روش های مختلف F.W./ B.W/H.F.W.B.W
ب) PCA,NCPA
ج) منیفولدها
د) شبکه های عصبی
۲- کاهش داده ها
الف) روش های پارامتریک که منجر به رگرسیون خواهند شد.
ب) غیرپارامتریک هیستوگرام،خوشه بندی، نمونه برداری، شبکه های عصبی و سیستم های فازی
۳- فشرده سازی اطلاعات
الف) با اتلاف
ب) بی اتلاف
انتقال داده ها:
- هموارسازی
- استخراج یا ساخت ویژگی )تبدیل ورودی به ویژگی)
- جمع بندی
- نرمال سازی داده (خطی، آماری، مقیاس ده دهی)
- گسسته سازی
- فازی سازی
- درخت های مفهومی
طبقه بندی
یکی از مباحث کلیدی در بحث یادگیری ماشین، آمار، داده کاوی و… است. طبقه بندی یکی از مهمترین رویکردی هایی است که می توان به وسیله آن مسائل داده کاوی را حل کرد. اساسا مهم ترین دانش بشر که توانسته به آن برسد دانش طبقه بندی است. بسیاری از علوم مثل علوم پزشکی به عنوان زیرشاخه علم طبقه بندی قرار می گیرند. به عنوان مثال یک پزشک نگاشتی از فضای مشاهدات به فضای بیماری ها و از فضای بیماری ها به فضای درمان انجام می دهد. یا یک کارگزاری بورس بر اساس مشاهدات و طبقه بندی های ایجاد شده استراتژی های سرمایه گذاری را معین می کند. اگر حجم داده ها انبوه باشد هوش انسانی دیگر جوابگو نیست و باید از هوش ماشین بهره گرفت. پس از ماشینی کرده طبقه بندی به الگوی زیر می رسیم:
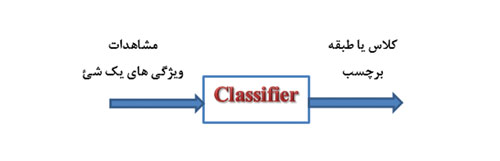
- اگر برچسب ها گسسته باشد مسئله طبقه بندی است و اگر پیوسته باشد رگرسیون است در هر صورت هر دو پیش بین مدل هستند.
- این برچسب ها در طبقه بندی ترتیب پذیر نیستند.
- اگر دانشی وجود داشته باشد که طبقه بندی بر اساس آن صورت گیرد مسئله طبقه بندی است و در غیر این صورت خوشه بندی مطرح می شود.
- کاربرد در تشخیص پزشکی، تقلب در مسائل مالی، تولید، پیش بینی عملکرد، پیش بینی فروش و…
طبقه بندی در دو مرحله انجام می شود:
- مرحله آموزش (تربیت)
- مرحله پیش بینی (آموزش یا طبقه بندی) کاربرد
مثال: اعطای وام با روش طبقه بندی
- اگر متقاضی جوان است، فرد امنی است.
- اگرمتقاضی درآمد بالایی دارد، فرد امنی است.
- اگر متقاضی میانسال است و درآمد کمی دارد، فرد امنی نیست.
امن بودن یا نبودن فرد از بررسی موارد قبلی بدست آمده است. برای مثال قبلا افراد جوانی وام گرفته اند اما توانایی پرداخت نداشته اند پس از این پس برای اعطای وام به این افراد باید احتیاط کرد.
مثال: پیش بینی فروش لپتاپ در یک منطقه با استفاده از درخت تصمیم
درخت تصمیم
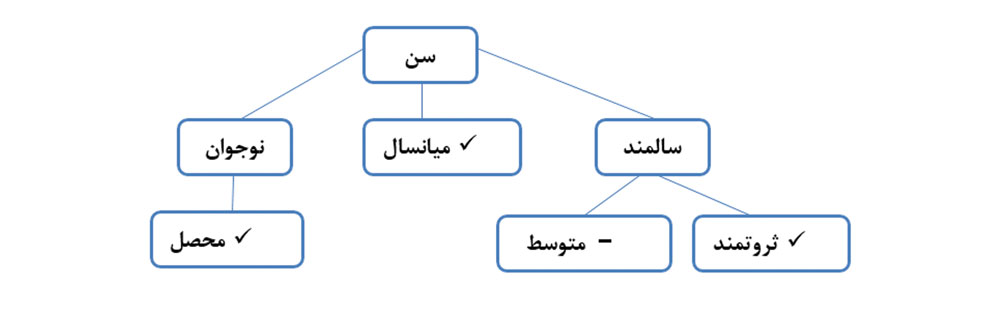
درخت به تعداد Leaf(Node هایی که فرزند نداند.) Rule دارند.
نحوه آموزش درخت تصمیم: مجموعه ای از اطلاعات را داریم و بررسی می کنیم که کدام ویژگی بیشترین تفکیک را ایجاد میکند. فرضا سن بیشترین تأثیر را دارد پس نود سن را ایجاد کرده و انشعابات را از نود اصلی مشخص می کنیم. برای مثال نوجوان، میانسال و سالمند. اگر تمامی محصل ها عین هم هستند دیگر تفکیک لازم نیست و در غیر این صورت تفکیک می کنیم برای مثال به دو گروه محصل و غیر محصل….
درخت تصمیم یک تابع است که ورودی آن مجموعه ای از داده ها است و خروجی آن درخت تصیم است.
TDT (D)=T
- یک درخت به نام T ساخته می شود.
- اگر همه اعضایD در یک کلاس هستند، یک گره برگ با برچسب کلاس مربوط ایجاد می کنیم.
- اگر فهرست اعضای جداکننده خالی است، یک با برچسب کلاسی که بیشترین عضو را دارد ایجاد می کنیم.
- بهترین ویژگی جداکننده را پیدا می کنیم.
- با توجه به مقادیر بهترین ویژگی تفکیک کننده انشعاباتی را ایجاد می کنیم.
- به ازای هر انشعاب j، مجموعه Dj شامل همه مقادیری است که در آن انشعاب صدق می کند. تابع TDT (Dj) را فراخوانی و نتیجه آن را به درخت اصلی(مادر) ملحق می کنیم.
- درخت T را(درخت مادر) به عنوان نتیجه بازمی گردانیم.
در نرم افزار متلب کلاس Classification Tree در Toolbox آمار به صورت یک بسته نرم افزاری پیاده سازی شده است و تمامی توابع لازم را شامل می شود و خروجی آن درخت تصمیم دو دویی است.
حل مثال از دسته بندی سه گروه گیاه در متلب
>> Load Fisheriris (فراخوانی یک دیتاست)
<< t=ClassificationTree.fit (meas.species)
داده ها در قسمت طبقه بندی می شوند:
| Test | Validation | Train |
| بعد از آموزش است و مجهول است.
مانند امتحان پایان ترم |
در حین آموزش است و مجهول است.
Overtraining- overfiting مانند امتحان میان ترم |
داده هایی که برای شکل گیری پیش بین حین آموزش استفاده می شود و کاملا معلوم است. مانند آموزش درس در کلاس |
اما اگر دادها به اندازه ای کم بودند که در امکان قرارگیری در این دسته بندی ها را نداشتند از الگوی Cross Validation استفاده می کنیم. به این صورت که داده ها را در دسته بندی های مختلف قرار می دهیم و در سناریوهای متفاوت هربار برخی داده را تست و برخی دیگر را آموزش می دهیم.
K-fold Cross Validation
| D | C | B | A |
| Train | Train | Train | Test |
| Train | Train | Test | Train |
| Train | Test | Train | Train |
| Test | Train | Train | Train |
قانون بیز
وقتی احتمال B به شرط A مشخص نیست ولی احتمال A به شرط B مشخص است این تئوری یاری بخش است.
P(A│B)*P(B)=P(B│A)*P(A)
P(A|B)→Posterior احتمال پسین
P(B|A)→likelihood
P(A)→Prior احتمال پیشین
P(B)→Normalizer نرمال کننده(معمولا به علت پیچیدگی در محاسبات با تقریب ۱ در نظرگرفته می شود.)
Naïve Bayesian Classifier
فرضا می خواهیم X (مشاهده)را در یکی از کلاس های C1,C2,…,Cm دسته بندی کنیم
X ∊ Cj اگر و تنها اگر P(Cj|X) > P(Ci|X) ,i≠j
Or j=〖argmax〗_(i ) P(Ci|X)
این روش زمانی که مشاهدات مستقل هستند مناسب است.
K-NN (K- Nearest neighbor)
K-NN و CBR (Case base reseaning) جزو Lazy classifier ها هستند.
روش های دیگر دسته بندی
- شبکه های بیزی که می تواند وابستگی بین مشاهدات را نیز مدل کند.
- Case-Based Reasoning
- الگوریتم های بهینه سازی هوشمند و تعاملی
- شبکه های عصبی مصنوعی ANN: MLP, RBF, SVM, LVQ
- سیستم های فازی
خوشه بندی (clustering- cluster Analysis- Automatic Classification- Data segmentation )
در دسته بندی learning supervisedو در مسائل خوشه بندی با unsupervised learning مواجه هستیم.
| Clustering | Classification |
| Unsupervised Learning | Supervised Learning |
| Learning by Example | Learning by observation |
چون خوشه بندی بدون معلم است مسأله ارزشمندتر و دانش خیز تری نسبت به دسته بندی است.
کاربردهای خوشه بندی
- در هوش تجاری به منظور دسته بندی مشتریان
- موتورهای جست و جو
- مدیریت پروژه و منابع
- کاهش رنگ
روش های خوشه بندی
۱- روش های مبتنی بر تقسیم بندی
این روش ها تعداد خوشه ها را تشکیل می دهند و معمولا برای هر شوخه یک میانه و نماینده دارند
Loid’s algorithm (k-means)
۲- روش های سلسله مراتبی
- پائین به بالا Agglomerative به طور مثال روش AGNES
- بالا به پائین Divisive به طور مثال روش DIANA
۳- روش های مبتنی بر چگالی یا توزیع
۴- روش های جدولی
مجموعه: اخبار و تازه ها
