ماشین بردار پشتیبان
در مبحث یادگیری ماشین، ماشینهای بردار پشتیبان (SVM که شبکه برداری پشتیبان نیز نامیده میشوند) مدلهای یادگیری تحت نظارتی هستند که با الگوریتمهای یادگیریای که داده را تحلیل و الگوها را شناسایی میکنند همکاری می نماید و برای دستهبندی و تحلیل رگرسیون استفاده میشوند. با داشتن مجموعهای از نمونههای آموزشی که مشخص شده است هر کدام به چه دستهای از دو دسته موجود متعلق هستند، یک الگوریتم آموزشی SVM مدلی را میسازد که نمونههای جدید را به دسته اول یا دوم تخصیص بدهد.
در مبحث یادگیری ماشین، ماشینهای بردار پشتیبان (SVM که شبکه برداری پشتیبان نیز نامیده میشوند) مدلهای یادگیری تحت نظارتی هستند که با الگوریتمهای یادگیریای که داده را تحلیل و الگوها را شناسایی میکنند همکاری می نماید و برای دستهبندی و تحلیل رگرسیون استفاده میشوند. با داشتن مجموعهای از نمونههای آموزشی که مشخص شده است هر کدام به چه دستهای از دو دسته موجود متعلق هستند، یک الگوریتم آموزشی SVM مدلی را میسازد که نمونههای جدید را به دسته اول یا دوم تخصیص بدهد.
این مسئله SVM را یک دستهبند (کلاسیفایر) خطی باینری غیراحتمالی میکند. یک مدل SVM نمونهها را به صورت نقاطی در فضا نشان میدهد و آنها را طوری نگاشت میکند که نمونههای متعلق به هر دسته توسط یک حاشیه مشخص که تا حد امکان عریض است، از یکدیگر جدا باشند. نمونههای جدید در همان فضا نگاشت شده و بر اساس اینکه کدام سمت حاشیه ذکر شده قرار گرفتهاند، پیشبینی میشود که به کدام دسته متعلق هستند.
علاوه بر اجرای دستهبندی خطی، SVM ها میتوانند به صورت مؤثری دستهبندی غیرخطی را با استفاده از kernel trick انجام داده و به صورت غیرمستقیم ورودیهایشان را به فضای ویژگی در ابعاد بالا نگاشت کنند.
انگیزش
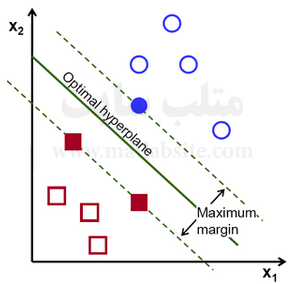
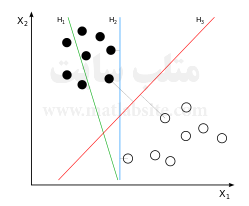
دستهبندی داده یک وظیفه رایج یادگیری ماشین است. فرض کنید تعدادی نقاط داده مفروض وجود دارند که هر کدام متعلق به یک کلاس از دو کلاس میباشند و هدف، تصمیمگیری در این مورد است که نقطههای داده جدید به کدام کلاس متعلق میباشند. در ماشینهای بردار پشتیبان، یک داده به صورت یک بردار p-بعدی (لیستی از p عدد) دیده شده و ما میخواهیم جداسازی این دادهها را با ابرصفحه (p-1) بعدی بررسی کنیم. به این ابرصفحه دستهبند یا کلاسیفایر خطی گفته میشود.
ابرصفحههای بسیاری وجود دارند که میتوانند دادهها را دستهبندی کنند. یک انتخاب منطقی برای بهترین ابرصفحه میتواند ابرصفحهای باشد که نشاندهنده بزرگترین حاشیه بین دو کلاس است. بدین ترتیب، ابرصفحهای را انتخاب میکنیم که فاصله آن تا نزدیکترین نقطه داده در هر سمت ابرصفحه، ماکزیمم باشد. اگر ابرصفحهای با این شرایط وجود داشته باشد، به آن ابرصفحه با بزرگترین حاشیه گفته میشود و دستهبند خطیای که تعریف میکند به نام دستهبند بزرگترین حاشیه خوانده میشود؛ معادل پرسپترون با پایداری بهینه.
رگرسیون
نسخهای از SVM برای حل رگرسیون در سال ۱۹۹۶ توسط ولادیمیر واپنیک، هریس دروکر، کریستوفر برگرز، لیندا کافمن و الکساندر سمولو ارائه شد. این متد، رگرسیون بردار پشتیبان نامیده میشود (SVR). مدل تولید شده با استفاده از دستهبندی بردار پشتیبان (که در بالا توصیف شد) تنها به زیرمجموعهای از دادههای آموزشی وابسته است زیرا تابع هزینه برای ساخت مدل، نقاط داده آموزشی که خارج از حاشیه واقع شدهاند را در نظر نمیگیرد.
به صورت مشابه، مدل تولید شده توسط SVR نیز تنها وابسته به زیرمجموعهای از دادههای آموزشی میباشد زیرا تابع هزینه برای ساخت مدل، هر داده آموزشیای که نزدیک به مدل پیشبینی باشد (با توجه به یک بازه/اپسیلون) را در نظر نمیگیرد. نسخه دیگری از SVM به نام ماشین بردار پشتیبان کمترین مربعات (LS-SVM) توسط سویکنز و واندوال ارائه شده است.
پیادهسازی
پارامترهای ابرصفحه با ماکزیمم حاشیه، برای حل مسائل بهینهسازی استخراج شدهاند. الگوریتمهای تخصصی متنوعی برای حل سریع مسئله QP که از SVM ها ناشی میشود وجود دارد که بیشتر مبتنی بر هیورستیکها جهت شکستن مسئله به بخشهای کوچکتر و قابل مدیریتتر میباشند. یک روش رایج، الگوریتم بهینهسازی مینیمال ترتیبی (SMO) است که مسئله را به زیرمسائل دو بعدی که میتوانند به صورت تحلیلی حل شوند تقسیم کرده و در نتیجه نیاز به یک الگوریتم بهینهسازی عددی را حذف میکند.
یک رویکرد دیگر استفاده از روش نقطه داخلی میباشد که از تکرارهای نیوتون-مانند برای یافتن راه حلی برای شرطهای Karush-Kuhn-Tucker مسائل اصلی و دوگان استفاده میکند. به جای حل دنبالهای از مسائل شکسته شده، این رویکرد مسئله را به صورت یکپارچه و کلی حل میکند. برای پرهیز از حل یک سیستم خطی شامل ماتریس کرنل بزرگ، اغلب یک تقریب رتبه پایین در kernel trick مورد استفاده قرار میگیرد.
نمونه خاصی از ماشینهای بردار پشتیبان میتواند توسط همان الگوریتمهایی که برای بهینه کردن رگرسیون منطقی استفاده میشود، به صورت موثرتر حل گردد. این دسته از الگوریتمها شامل زیر-گرادیان نزولی (مانند PEGASOS) و مختص نزولی (مانند LIBLINEAR) میشوند. SVM های کرنل عمومی میتوانند به وسیله زیر-گردایان نزولی (مانند P-packSVM) به صورت موثرتری حل شوند، به خصوص وقتی موازیسازی مجاز باشد.
SVM های کرنل در بسیاری از تولکیتهای یادگیری ماشین شامل LIBSVM، MATLAB، SVMlight، scikit-learn، Shogun, Weka، Shark، JKernelMachines و غیره موجود میباشند.
کاربرد
SVM ها میتوانند برای حل مسائل مختلف دنیای واقعی استفاده شوند. SVM ها در طبقهبندی متن و فرامتن موثر هستند زیرا میتوانند به صورت محسوسی نیاز به نمونههای آموزشی برچسبدار را در هر دو حالت inductive و transductive کاهش دهند.
دستهبندی تصاویر نیز میتواند توسط SVM انجام بگیرد. نتایج آزمایشات نشان میدهند که SVM ها بعد از سه تا چهار دور دریافت فیدبک، به دقت جستجوی بسیار بالاتری از روشهای سنتی پالایش درخواستها دست مییابند.
SVM ها همچنین در علوم پزشکی برای دستهبندی پروتئینها کاربرد دارند و میتوانند بیش از %۹۰ ترکیبات را به صورت صحیحی طبقهبندی کنند. کاراکترهای دستنویس نیز میتوانند با استفاده از SVM شناسایی شوند.
مراجع مطالعاتی و منابع آموزشی مهم
در این بخش، قصد داریم منابع آموزشی و مراجع مطالعاتی در زمینه ماشین بردار پشتیبان را معرفی کنیم. اگر شما نیز قصد دارید که در یک کار پژوهشی، پروژه دانشگاهی یا صنعتی، و یا در مسیر علایق شخصی تان، ماشین بردار پشتیبان را فرا بگیرید و در خصوص نحوه پیاده سازی و کاربردهای این ابزارهای مفید، اطلاعاتی را کسب نمایید، حتما پیشنهاد می کنیم که در ادامه با ما همراه باشید.
کتابهای خارجی
 |
عنوان: An Introduction to Support Vector Machines and Other Kernel-based Learning Methods ترجمه عنوان: مقدمه ای بر ماشین های بردار پشتیبان و سایر روش های یادگیری مبتنی بر هسته مولف: Nello Cristianini سال چاپ: ۲۰۰۰ انتشارات: Cambridge University لینک دسترسی: لینک |
 |
عنوان: Knowledge Discovery with Support Vector Machines ترجمه عنوان: کشف دانش با ماشین های بردار پشتیبان مولف: Lutz H. Hamel سال چاپ: ۲۰۰۹ انتشارات: Wiley لینک دسترسی: لینک |
 |
عنوان: Support Vector Machines ترجمه عنوان: ماشین های بردار پشتیبان مولف: Ingo Steinwart سال چاپ: ۲۰۰۸ انتشارات: Springer لینک دسترسی: لینک |
منابع آموزشی آنلاین
 |
عنوان: آموزش جامع ماشین های بردار پشتیبان یا SVM در متلب مدرس: دکتر سیدمصطفی کلامی هریس مدت زمان: ۵ ساعت و ۵۱ دقیقه نحوه استفاده: دریافت به صورت لینک دانلود و بر روی DVD زبان: فارسی نحوه آموزش: تئوری و عملی ارائه دهنده: سازمان علمی-آموزشی فرادرس لینک دسترسی: لینک |
مجموعه: شبکه های عصبی, یادگیری ماشینی
